
Storage
Computer storage is a hardware component that allows for the storage and retrieval of digital information. It is categorized into two main types:
- Primary storage (RAM, cache, ROM) for fast, temporary access to active data, and
- Secondary storage (hard drives, SSDs, cloud storage) for long-term, permanent data retention.
Storage Hardware and Architectures
Section titled “Storage Hardware and Architectures”Common Disk Types
Section titled “Common Disk Types”There are a number of different hard disk types, each of which is characterized by the type of data bus they are attached to, and other factors such as speed, capacity, how well multiple drives work simultaneously, etc.
SATA (Serial Advanced Technology Attachment) : SATA disks were designed to replace the old IDE drives. They offer a smaller cable size (7 pins), native hot swapping, and faster and more efficient data transfer. They are seen as SCSI devices.
SCSI (Small Computer Systems Interface) : SCSI disks range from narrow (8 bit bus) to wide (16 bit bus), with a transfer rate from about 5 MB per second (narrow, standard SCSI) to about 160 MB per second (Ultra-Wide SCSI-3). SCSI has numerous versions such as Fast, Wide, and Ultra, Ultrawide.
SAS (Serial Attached SCSI) : SAS uses a newer point-to-point serial protocol, has a better performance than SATA disks and is better suited for servers. See the “SAS vs SATA: What’s the Difference” article by Zach Cabading to learn more.
USB (Universal Serial Bus) : These include flash drives and floppies. And are seen as SCSI devices.
SSD (Solid State Drives) : Modern SSD drives have come down in price, have no moving parts, use less power than drives with rotational media, and have faster transfer speeds. Internal SSDs are even installed with the same form factor and in the same enclosures as conventional drives. SSDs still cost a bit more, but price is decreasing. It is common to have both SSDs and rotational drives in the same machines, with frequently accessed and performance critical data transfers taking place on the SSDs.
IDE and EIDE (Integrated Drive Electronics, Enhanced IDE) : These are obsolete.
Disk Geometry
Section titled “Disk Geometry”Rotational disks are composed of one or more platters and each platter is read by one or more heads. Heads read a circular track off a platter as the disk spins. Circular tracks are divided into data blocks called sectors.
Historically, disks were manufactured with sectors of 512 bytes; 4 KB is now most common by far; larger sector sizes can lead to faster transfer speeds. Linux still uses a logical sector size of 512 bytes for backward compatibility, but this is simply for pretend in software. A cylinder is a group which consists of the same track on all platters.
The physical structural image has become less and less relevant as internal electronics on the drive actually obscure much of it. Furthermore, SSDs have no moving parts or anything like the above ingredients, and for SSDs these geometry concepts make no sense.
we can see the geometry with fdisk:
sudo fdisk -l /dev/sdc |grep -i sector
Output:
Disk /dev/sdc: 1.8 TiB, 2000398934016 bytes, 3907029168 sectorsUnits: sectors of 1 * 512 = 512 bytesSector size (logical/physical): 512 bytes / 4096 bytesExternal Storage Types - DAS, NAS and SAN
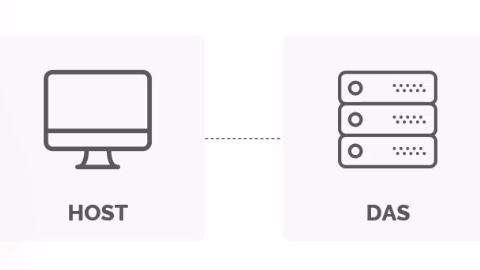
Section titled “External Storage Types - DAS, NAS and SAN”DAS (Direct Attached Storage)
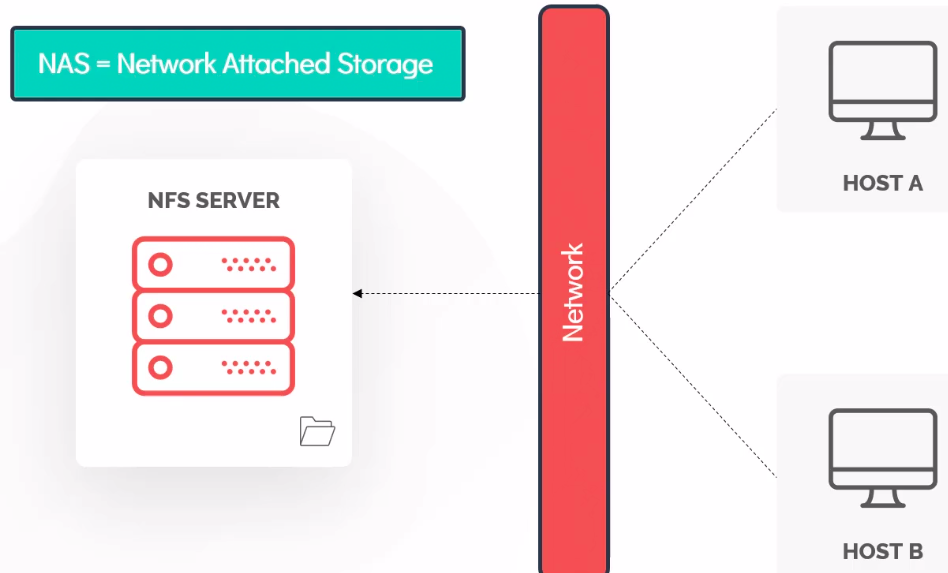
NAS (Network Attached Storage)
SAN (Storage Area Network)
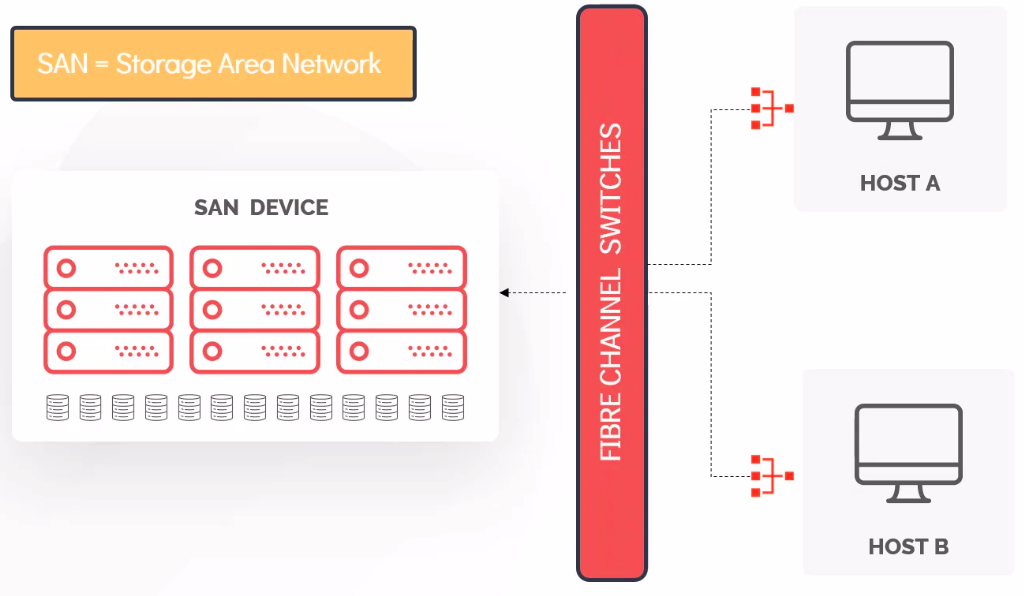
| DAS | NAS | SAN |
|---|---|---|
| Block Storage | NFS/CIFS | FC or iSCsI |
| Fast and Reliable | Reasonably Fast and Reliable | Block Storage |
| Affordable | File Based Storage | Fast, Secure and Reliable |
| Dedicated to single host | Shared Storage | High Availability |
| ldeal tor small businesses | Not suitable for OS install | Expensive |
A Linux file system is a structured collection of files on a disk drive or a partition.
Disk Partitioning
Section titled “Disk Partitioning”What is a Partition?
Section titled “What is a Partition?”-
A partition is a physically contiguous section of a disk, or what appears to be so in some advanced setups. It is a segment of memory and contains some specific data.
-
In machine, there can be various partitions of the memory. Generally, every partition contains a file system.
-
The general-purpose computer system needs to store data systematically so that we can easily access the files in less time. It stores the data on hard disks or some equivalent storage type. Reasons for maintaining the file system:
-
Primarily the computer saves data to the RAM storage; it may lose the data if it gets turned off. However, there is non-volatile RAM (Flash RAM and SSD) that is available to maintain the data after the power interruption.
-
Data storage is preferred on hard drives as compared to standard RAM as RAM costs more than disk space. The hard disks costs are dropping gradually comparatively the RAM.
The Linux file system contains the following sections:
- The root directory (
/) - A specific data storage format (EXT3, EXT4, BTRFS, XFS and so on)
- A partition or logical volume having a particular file system.
Why Partition?
Section titled “Why Partition?”There are multiple reasons as to why it makes sense to divide your system data into multiple partitions, including:
- Separation of user and application data from operating system files
- Sharing between operating systems and/or machines
- Security enhancement by imposing different quotas and permissions for different system parts
- Size concerns; keeping variable and volatile storage isolated from stable
- Performance enhancement of putting most frequently used data on faster storage media
- Swap space can be isolated from data and also used for hibernation storage.
The reasons to have distinct partitions include increased granularity of security, quota, settings or size restrictions. You could have distinct partitions to allow for data protection.
A common partition layout contains a /boot partition, a partition for the root filesystem /, a swap partition, and a partition for the /home directory tree.
Keep in mind that it is more difficult to resize a partition after the fact than during install/creation time. Plan accordingly.
Sizing Up Partitions
Section titled “Sizing Up Partitions”Most Linux systems should use a minimum of two partitions.
- root (
/) is used for the filesystem. Most installations will have more than one filesystem on more than one partition, which are joined together at mount points. It is difficult with most filesystem types to resize the root partition, but using LVM can make this easier. While it is certainly possible to run Linux with just the root partition, most systems use more partitions to allow for easier backups, more efficient use of disk drives, and better security. - Swap is used as an extension of physical memory. The usual recommendation is swap size should be equal to physical memory in size; sometimes twice that is recommended. However, the correct choice depends on the related issues of system use scenarios as well as hardware capabilities. Adding more and more swap will not necessarily help because at a certain point it becomes useless. One will need to either add more memory or re-evaluate the system setup.
On older rotational hard drive media, it may make more sense to have a separate swap partition, but on SSD-type media, this is unimportant. However, one still may want to put swap on slower and probably cheaper hardware. This is true whether you use a partition or a file, which is becoming a more prevalent choice.
Some distributions, including Ubuntu, default to use of a swap file rather than a partition:
- It is more flexible (resizing is easier, for example)
- It can be more dangerous, however, if error or bug spreads corruption
Types of Partitions
Section titled “Types of Partitions”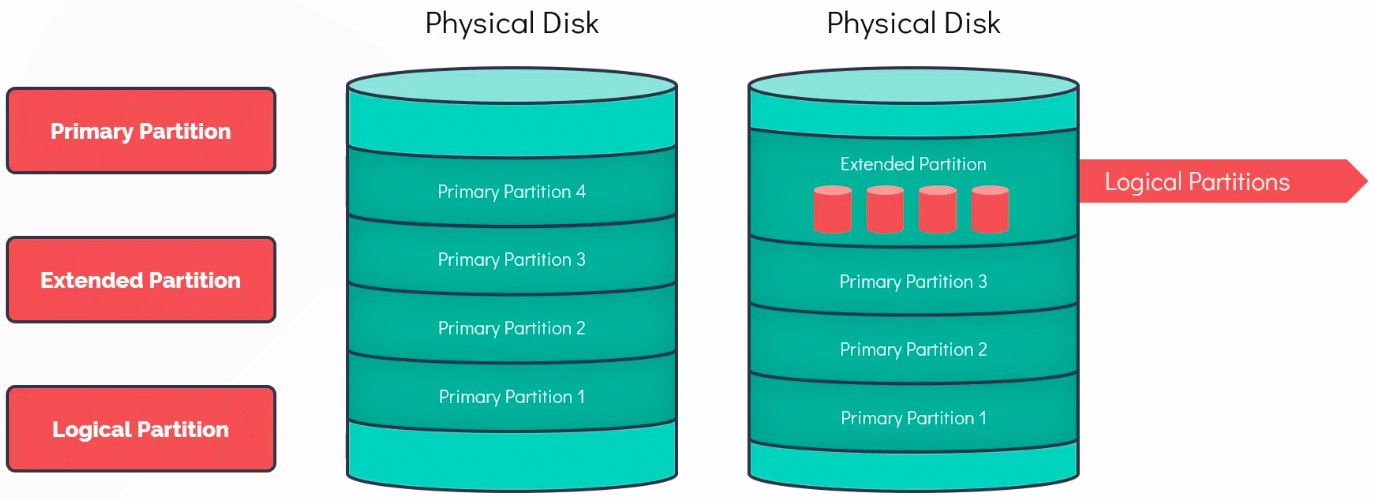
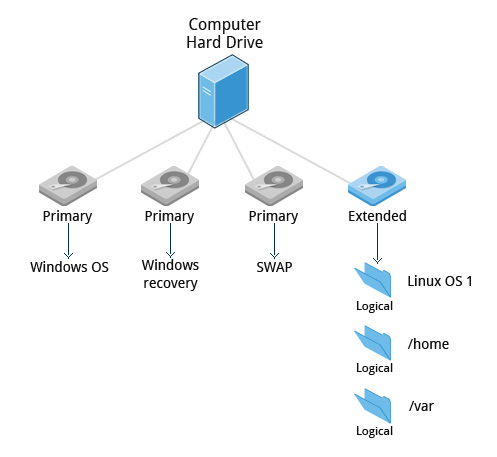
- Primary Partition: Type of partition which is used to boot an OS. Traditionally limited to 4 Primary Partitions per disk.
- Extended Partition: Cannot be used on its own and can host logical partitions in it. Its purpose is specifically to contain logical partitions. It acts as a container to overcome the four-primary-partition limit of the MBR scheme.
- Logical Partition: How a disk is partitioned is defined by partition table such as MBR (Master Boot Record), GPT (GUID partition table)
Partition Organization
Section titled “Partition Organization”Disks are divided into partitions. A partition is a physically contiguous region on the disk. On the most common architectures, there are two partitioning schemes in use:
- MBR (Master Boot Record)
- GPT (GUID Partition Table)
MBR dates back to the early days of MSDOS. When using MBR, a disk may have up to four primary partitions. One of the primary partitions can be designated as an extended partition, which can be subdivided further into logical partitions with 15 partitions possible.
When using the MBR scheme, if we have a SCSI, for example, /dev/sda, then /dev/sda1 is the first primary partition and /dev/sda2 is the second primary partition. If we created an extended partition /dev/sda3, it could be divided into logical partitions. All partitions greater than four are logical partitions (meaning contained within an extended partition). There can only be one extended partition, but it can be divided into numerous logical partitions.
GPT is on all modern systems and is based on UEFI (Unified Extensible Firmware Interface). By default, it may have up to 128 primary partitions. When using the GPT scheme, there is no need for extended partitions. Partitions can be up to 233 TB in size (with MBR, the limit is just 2TB).
MBR Partition Table
Section titled “MBR Partition Table”The disk partition table is contained within the disk’s Master Boot Record (MBR), and is the 64 bytes following the 446 byte boot record. One partition on a disk may be marked active. When the system boots, that partition is where the MBR looks for items to load.
The structure of the MBR is defined by an operating system-independent convention.
- The first 446 bytes are reserved for the program code. They typically hold part of a boot loader program.
- The next 64 bytes provide space for a partition table of up to four entries. The operating system needs this table for handling the hard disk.
On Linux systems, the beginning and ending address in CHS is ignored.

Each entry in the partition table is 16 bytes long, and describes one of the four possible primary partitions. The information for each is:
- Active bit
- Beginning address in cylinder/head/sectors (CHS) format
- Partition type code, indicating: xfs, LVM, ntfs, ext4, swap, etc.
- Ending address in CHS
- Start sector, counting linearly from 0
- Number of sectors in partition.
Linux only uses the last two fields for addressing, using the linear block addressing (LBA) method.
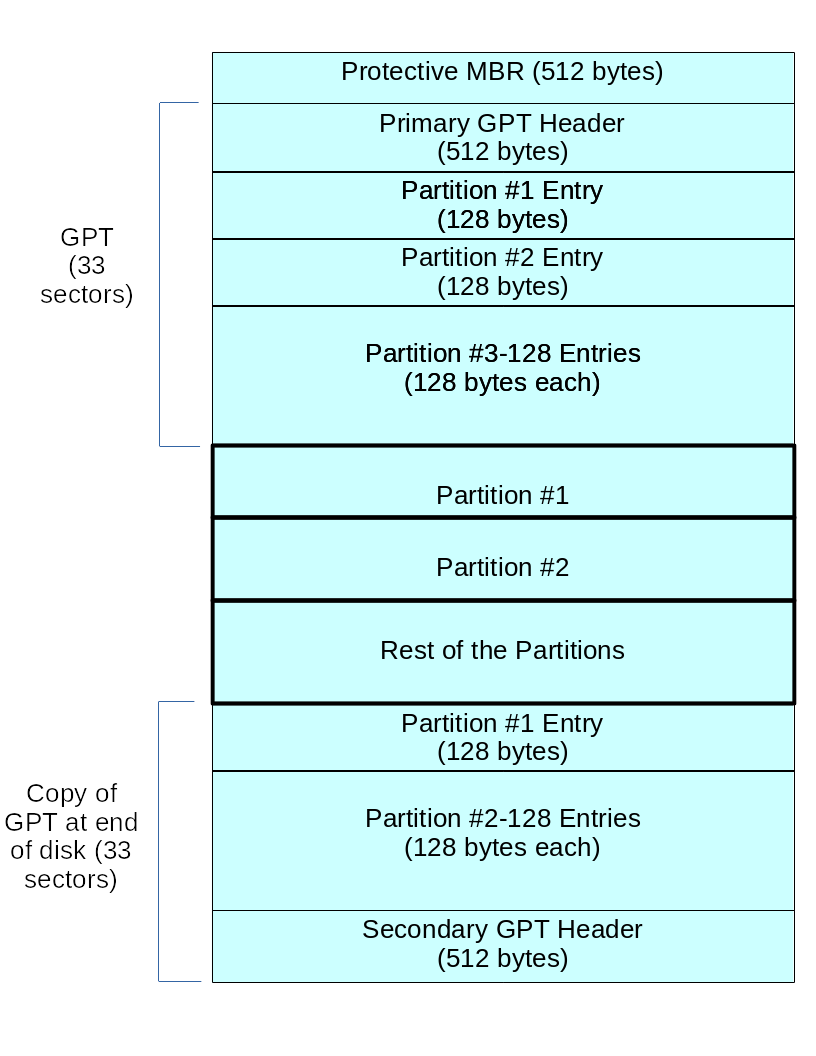
GPT Partition Table
Section titled “GPT Partition Table”Modern hardware comes with GPT support, MBR support will gradually fade away. The Protective MBR is for backwards compatibility, so UEFI systems can be booted the old way. There are two copies of the GPT header, at the beginning and at the end of the disk, describing metadata:
- List of usable blocks on disk
- Number of partitions
- Size of partition entries. Each partition entry has a minimum size of 128 bytes.
The blkid utility shows information about partitions.
#On a modern UEFI/GPT system run the following command:sudo blkid /dev/sda8
Output:/dev/sda8: LABEL="RHEL8" UUID="53ea9807-fd58-4433-9460-d03ec36f73a3" BLOCK_SIZE="4096" TYPE="ext4"↪ PARTUUID="0c79e35b-e58b-4ce3-bd34-45651b01cf43"
#On a legacy MBR system use this command:sudo blkid /dev/sdb2
Output:/dev/sdb2: LABEL="RHEL8" UUID="6921b738-1e36-429a-89be-8b97cf2f0556" BLOCK_SIZE="4096" TYPE="ext4"↪ PARTUUID="00022650-02"The GPT partition also gives a PARTUUID which describes the partition and stays the same even if the filesystem is reformatted. If the hardware supports it, it is possible to migrate an MBR system to GPT, but it is not hard to brick the machine while doing so. Thus, usually the benefits are not worth the risk.
How Linux Identifies Storage
Section titled “How Linux Identifies Storage”Block and Character Devices
Section titled “Block and Character Devices”When a program reads or writes data from a file, the requests go to a kernel driver. If the file is a regular file, the data is handled by a file_system driver and it is typically stored in zones on a disk or other storage media, and the data that is read from a file is what was previously written in that place. There are other file types for which different things happen.
When data is read or written to a device file, the request is handled by the driver for that device. Each device file has an associated number which identifies the driver to use. What the device does with the data is its own business.
-
Block devices (also called block special files) usually behave a lot like ordinary files
-
They are an array of bytes, and the value that is read at a given location is the value that was last written there.
-
Data from block device can be cached in memory and read back from cache; writes can be buffered.
-
Block devices are normally seekable (i.e. there is a notion of position inside the file which the application can change).
-
The name “block device” comes from the fact that the corresponding hardware typically reads and writes a whole block at a time (e.g. a sector on a hard disk).
-
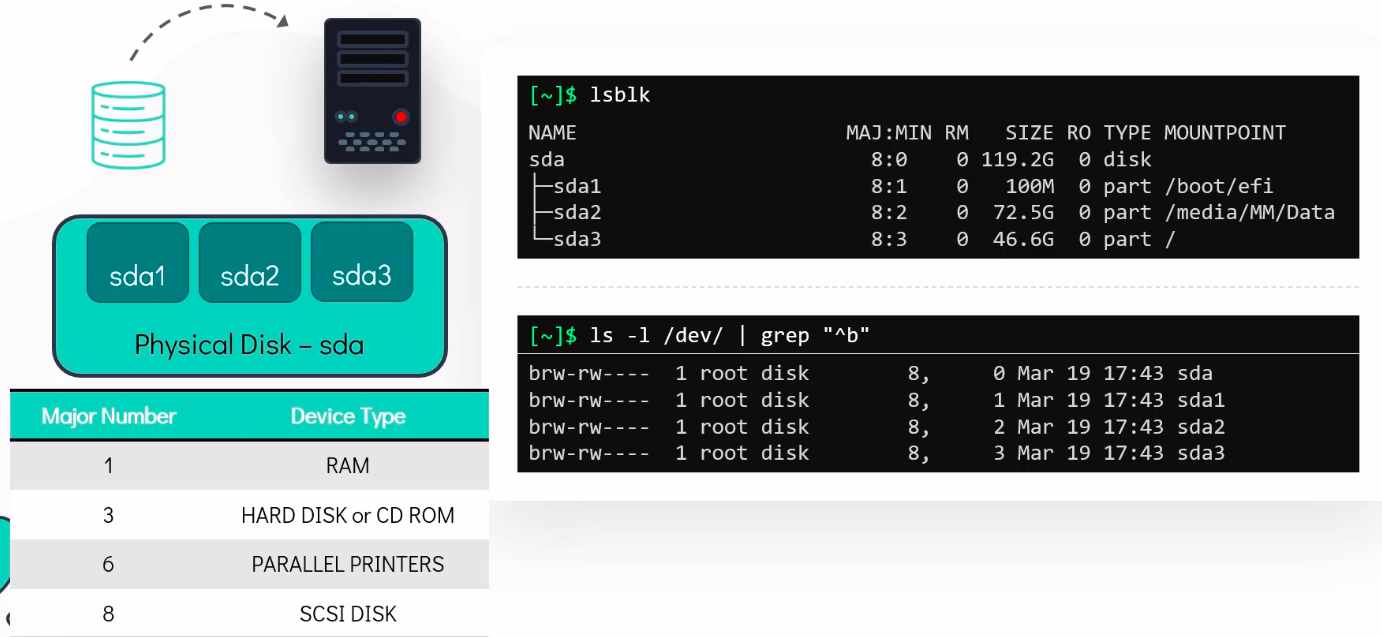
Each block device has a Major and Minor number
- Major number is used to identify the type of the block device.
- The Minor number is used to distinguish individual physical or logical devices.
-
-
Character devices (also called character special files) behave like pipes, serial ports, etc.
- Writing or reading to them is an immediate action. What the driver does with the data is its own business.
- Writing a byte to a character device might cause it to be displayed on screen, output on a serial port, converted into a sound, Reading a byte from a device might cause the serial port to wait for input, might return a random byte (
/dev/urandom). - The name “character device” comes from the fact that each character is handled individually.
Naming Disk Devices and Device Nodes
Section titled “Naming Disk Devices and Device Nodes”The Linux kernel interacts at a low level with disks through device nodes normally found in the/dev` directory. Normally, device nodes are accessed only through the infrastructure of the kernel’s Virtual File System; raw access through the device nodes is an extremely efficient way to destroy a filesystem.
For an example of proper raw access, you can format a partition, as in this command:
sudo mkfs.ext4 /dev/sda9Device nodes for SCSI and SATA disks follow a simple xxy[z] naming convention, where
-
xxis the device type (usually sd), -
yis the letter for the drive number (a, b, c, etc.), and -
zis the partition number: -
The first hard disk is
/dev/sda -
The second hard disk is
/dev/sdb -
Etc.
Partitions are also easily enumerated, as in:
/dev/sdb1is the first partition on the second disk/dev/sdc4is the fourth partition on the third disk.
In the above, sd means SCSI or SATA disk.
Doing ls -l /dev will show you the current available disk device nodes.
blkid is a utility to locate block devices and report on their attributes. It works with the libblkid library. It can take as an argument a particular device or list of devices.
sudo blkid /dev/sda/dev/sda: PTUUID="e7495134-61a2-473c-a31e-3c573a3d8e3e" PTTYPE="gpt"It can determine the type of content (e.g. filesystem, swap) a block device holds, and also attributes (tokens, NAME=value pairs) from the content metadata (e.g., LABEL or UUID fields).
blkid will only work on devices which contain data that is finger-printable: e.g., an empty partition will not generate a block-identifying UUID.
blkid has two main forms of operation:
- either searching for a device with a specific NAME=value pair, or
- displaying NAME=value pairs for one or more devices.
Without arguments, it will report on all devices.
A related utility is lsblk which presents block device information in a tree format.
lsblkNAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTSsda 8:0 0 465.8G 0 disk├─sda1 8:1 0 1G 0 part /boot/efi├─sda2 8:2 0 1G 0 part /boot└─sda3 8:3 0 463.8G 0 /homezram0 251:0 0 8G 0 disk [SWAP]nvme0n1 259:0 0 476.9G 0 disk└─nvme0n1p1 259:1 0 476.9G 0 part /mnt/storage