
Pipeline Design Patterns
CI/CD pipelines are software systems. The same design principles that make application code maintainable, testable, and scalable apply to the pipeline itself. Creational design patterns - originally defined in object-oriented software design - map directly to the decisions made when architecting how pipelines create, provision, and manage resources.
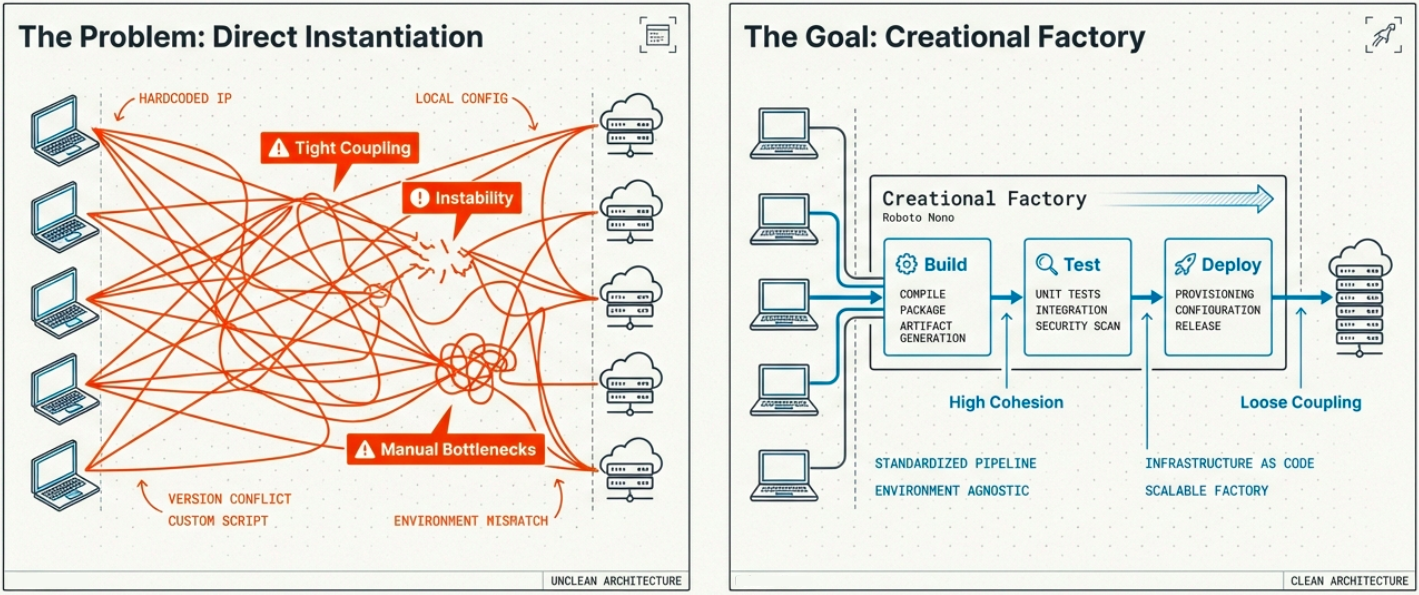
Creational Design Patterns
Section titled “Creational Design Patterns”Creational patterns abstract the process of object creation from the rest of the system. Instead of hardcoding how things are built (tight coupling), the system delegates creation through well-defined interfaces (loose coupling). In a CI/CD context, this translates to how pipelines provision environments, create artifacts, and configure runners.
The five canonical creational patterns and their CI/CD applications:
| Pattern | Core concept | CI/CD application |
|---|---|---|
| Singleton | Only one instance exists; provides a single global access point | Shared configuration file, centralized logging service, or single database connection pool shared across all pipeline jobs |
| Factory Method | Subclasses decide which concrete object to instantiate | Pipeline creates a RegularBuild or NightlyBuild job type without the core pipeline needing to know the specifics of either |
| Abstract Factory | Creates families of related objects without specifying their concrete classes | Automatically provisions the correct paired environment (staging server + staging DB vs. production server + production DB) based on the deployment target |
| Builder | Constructs complex objects step-by-step | Sequential pipeline stages: Code Check → Test → Build → Deploy → Monitor - each stage validated before the next begins |
| Prototype | Clones existing objects instead of building from scratch | Container images serve as prototypes, cloned and deployed across pipeline stages for consistent, fast test execution |
Scalability and Resilience
Section titled “Scalability and Resilience”Two foundational principles underpin all creational pattern usage in CI/CD:
Scalability - A pipeline must gracefully handle varying workloads by scaling resources up or down on demand. Creational patterns enable this by decoupling object creation from the pipeline logic, so the number of instances can be adjusted without rewriting the pipeline itself.
Resilience - A pipeline must remain partially operational even when components fail. Resilience is designed in, not bolted on:
- Redundancy - Run multiple instances in parallel so a single failure doesn’t halt the pipeline
- Circuit breakers - Halt cascading failures at a defined boundary so isolated failures don’t propagate system-wide
In practice, these principles are realized through Kubernetes clusters, horizontal pod autoscalers, and serverless functions - but the architectural intent comes from the pattern layer.
Cloud-Native Pipeline Practices
Section titled “Cloud-Native Pipeline Practices”Traditional creational patterns are conceptual in nature. In cloud-native CI/CD, they translate into concrete practices and infrastructure standards. These cloud-native patterns represent a fundamental shift in how deployment is executed - optimized for the dynamic, scalable, resilient nature of cloud environments.
The goal is a declarative, infrastructure-agnostic approach to automation: define the desired state, and let the toolchain converge on it.
| Practice | What it means | Pattern alignment |
|---|---|---|
| Immutable Infrastructure | Updates are made by replacing components entirely - not by modifying running systems. Each deployment is a fresh, exact replica. | Prototype - new instances replace old ones |
| Microservices Architecture | Applications decompose into independently deployable services that communicate via APIs | Abstract Factory - each service gets its own provisioning factory |
| Infrastructure as Code (IaC) | Infrastructure is defined as version-controlled code (Terraform, Pulumi, Bicep). Changes are repeatable, reviewable, and auditable. | Builder - infrastructure is assembled step-by-step |
| Configuration as Code | Build, deployment, and environment config lives alongside application code in version control | Singleton - one canonical config, always in sync |
| Containerization + Orchestration | Applications are packaged with all dependencies into containers, orchestrated by Kubernetes | Prototype + Factory Method |
| GitOps | Git is the single source of truth. Production state is continuously reconciled against the Git repo by a controller (Argo CD, Flux). | Singleton - Git state is the one authority |
| Observability | Comprehensive logging, metrics, and distributed tracing across all pipeline stages | - |
| Continuous Feedback | Every stage of the pipeline (tests, quality checks, security scans) feeds results back into the delivery loop | - |
Pipeline Workflow
Section titled “Pipeline Workflow”When these patterns are fully integrated, a modern CI/CD pipeline flows through predictable, validated stages:
| Stage | What happens |
|---|---|
| Code & Source Control | Developers work in short-lived feature branches. Work is merged to a release/main branch only after review and test. |
| CI Trigger | A push or PR event triggers CI: code is built, dependencies resolved, initial automated tests run |
| Build | Compilation, artifact creation, Docker image build. Artifact is signed and pushed to the registry. |
| Test | Automated unit, integration, and contract tests. Coverage gates are enforced. |
| QA | Extended quality assurance - manual exploratory testing, performance tests, regression suites |
| Staging | Pre-production environment mirrors production. Final validation before live traffic. |
| Production | Release. Traffic shifted using blue-green, canary, or rolling update strategy. |
| Monitoring & Alerts | Observability tools track error rates, latency, and business metrics. Alerts trigger rollbacks if SLOs breach. |
Key Cloud Components
Section titled “Key Cloud Components”Containerization
Section titled “Containerization”Containers encapsulate an application’s code, runtime, system tools, and dependencies into a single portable unit. This eliminates environment drift across pipeline stages.
How containerization embodies each creational pattern:
| Pattern | How containers apply it |
|---|---|
| Prototype | A base container image serves as the prototype - cloned, modified, and deployed across stages without rebuilding from scratch each time |
| Factory Method | A container runtime (Docker daemon, containerd) acts as the factory - the pipeline requests a Java build image or a Python test image without knowing how each is assembled |
| Builder | A Dockerfile separates construction (layers) from execution. The multi-stage Dockerfile is the Builder pattern made concrete |
| Singleton | Kubernetes ConfigMaps and Secrets provide a single source of truth for shared configuration, injected uniformly across all running containers |
Microservices Architecture
Section titled “Microservices Architecture”Microservices decompose a monolithic application into independently deployable services communicating via HTTP APIs or message brokers.
In CI/CD, this means each service has its own pipeline. Each service ships on its own schedule. Three infrastructure elements bind them together:
- Service discovery - Services dynamically locate each other without hardcoded addresses (Consul, Kubernetes DNS)
- API gateways - A single entry point handles routing, authentication, and rate limiting for all inbound requests
- Isolated data domains - Each service owns its own database schema; cross-service data access goes through APIs, never direct DB links
Serverless
Section titled “Serverless”Serverless computing abstracts all infrastructure management. Developers deploy functions; the platform handles provisioning, scaling, and availability.
Serverless introduces unique CI/CD pipeline considerations compared to traditional deployments:
| Consideration | What it means |
|---|---|
| Function-based deployment | Each function is deployed and versioned independently - not as part of a monolithic artifact |
| Event-driven testing | Tests must simulate the event payloads that trigger functions - traditional integration test patterns don’t map cleanly |
| IaC dependency | Serverless infrastructure (API Gateway, event sources, IAM permissions) must be provisioned via IaC on every pipeline run |
| Cold start management | Functions shut down when idle to save cost, introducing latency on first invocation. Warm-up strategies must be tested in the pipeline |
DevSecOps: Security in the Pipeline
Section titled “DevSecOps: Security in the Pipeline”Security is not a pipeline phase - it is a property of every phase. DevSecOps integrates security practices into the standard development and delivery workflow, shifting security left from the post-deployment audit to the pre-commit review.
The shift-left principle: security problems are dramatically cheaper to fix when caught during development than after deployment. Every hour a vulnerability sits in production costs more than an hour of prevention.
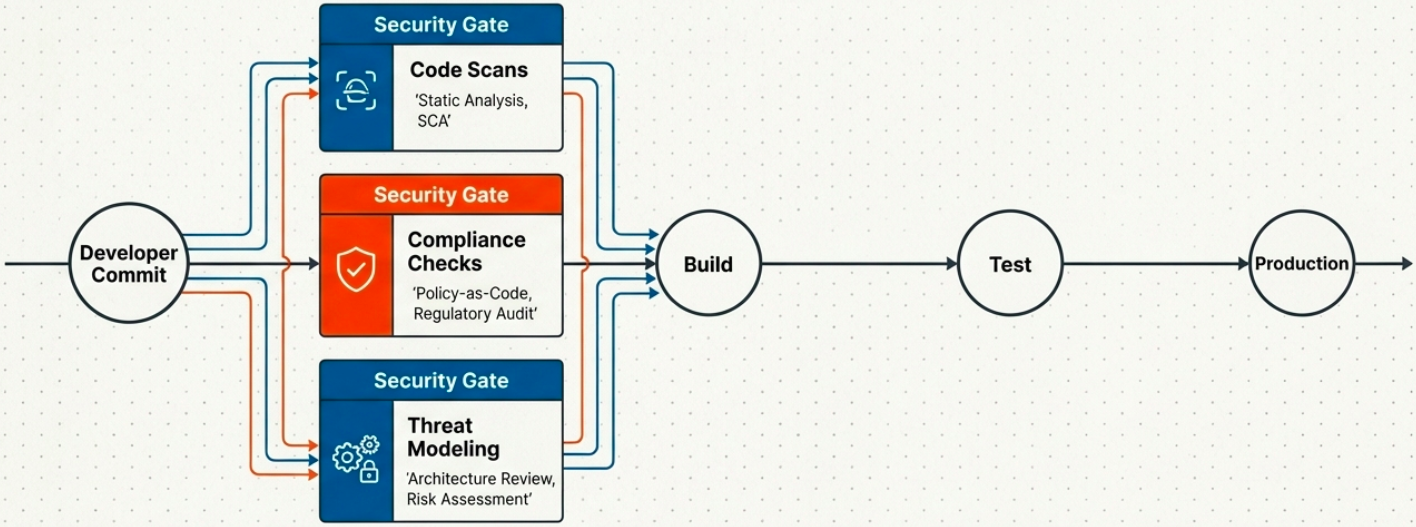
Security Practices by Layer
Section titled “Security Practices by Layer”| Layer | What to implement |
|---|---|
| Application code | SAST (static analysis), SCA (dependency scanning for known CVEs), threat modeling, code provenance tracking |
| Container and IaC | Image scanning for known vulnerabilities, Dockerfile hardening checks, IaC security linting (Checkov, tfsec) |
| Secrets management | No secrets in code or pipeline definitions. Use dedicated secrets stores (Vault, AWS Secrets Manager, Azure Key Vault) with scoped access |
| Policy enforcement | Policy as code (OPA, Conftest) automatically enforces organizational standards - no manual review gate required |
Integrated Security Workflow
Section titled “Integrated Security Workflow”When security is fully pipeline-integrated, the flow looks like:
- Developer pushes code → pipeline triggers
- SAST and SCA scans run - results annotated on the PR, blocking merge if critical findings exist
- Compliance checks run - policy engine evaluates the change against organizational and regulatory rules
- If all gates pass → artifact is built and deployed to test environment
- Automated tests + DAST (dynamic security testing against running app) run
- Only after all gates pass → artifact promoted to production
Scaling and Optimization
Section titled “Scaling and Optimization”A pipeline that works well at 5 developers and 1 service will break down at 50 developers and 20 services unless scaling is designed in from the start.
Prerequisites
Section titled “Prerequisites”- Know your patterns - The Singleton pattern creates bottlenecks at scale because it serializes access to a single instance. Identify which patterns your pipeline uses and understand their concurrency constraints.
- Microservices or serverless from the start - Monolithic pipeline architectures cannot scale horizontally. Independent service pipelines can.
- Containerize everything - Container orchestration is the primary mechanism for efficient, elastic pipeline worker scaling.
Optimization Strategies
Section titled “Optimization Strategies”| Strategy | What it achieves |
|---|---|
| Parallelize test stages | Run unit tests, linting, and security scans simultaneously instead of sequentially. Eliminates the largest lead time bottleneck. |
| Cache aggressively | Cache dependencies, Docker layers, and compiled artifacts between runs. Reduces build time by 40–80% in most projects. |
| AI-assisted code review | Tools like DeepCode detect bugs and security vulnerabilities at the code level. Akamas uses machine learning to autonomously optimize software configurations and resource allocation. |
| IaC standardization | Use Terraform, OpenTofu, Ansible, or Chef to provision environments consistently. Eliminates “works in CI but not prod” failures caused by environment drift. |
| Autoscaling runners | Use Kubernetes-based autoscalers or cloud-native runner fleets that scale to zero when idle and scale out under load. |
Best Practices Summary
Section titled “Best Practices Summary”| Practice | Why it matters |
|---|---|
| Identify bottlenecks before optimizing | Premature optimization wastes time on the wrong constraints |
| Use microservices to enable independent scaling | One slow service shouldn’t block all other deployments |
| Automate and standardize deployment processes | Reduces human error and enables reliable, repeatable releases |
| Implement feedback loops at every stage | Feedback is the mechanism that makes continuous improvement possible |
| Choose tools based on compatibility, not familiarity | Toolchain friction compounds as teams grow - invest in interoperability early |
| Avoid single points of failure | Proactively design redundancy into runners, registries, and deployment tooling |
| Monitor proactively, not reactively | AI-powered monitoring tools surface degradation trends before they become incidents |