
Modules & Design
Good infrastructure architecture is not a one-time decision. It is a continuous practice of keeping the system easy and safe to change - the same goal software engineers apply to application code, applied to the infrastructure that runs it. The primitive purpose of Modules to exist is - Versioning, Distribution, and Sharing.
Evolutionary Architecture
Section titled “Evolutionary Architecture”Traditional infrastructure architecture operates on a flawed premise: that the initial design will remain stable once deployed - like a bridge or a building. In practice, infrastructure must evolve continuously to support new features, security patches, performance improvements, and architectural scale changes.
The friction teams experience when changing infrastructure rarely comes from the code itself. It comes from complex design and implicit dependencies, combined with a lack of tooling and process that makes changes routine. Evolutionary architecture addresses this directly: design infrastructure so that both small and large changes can be made incrementally, safely, and without fear.
This philosophy maps directly to Agile and Lean methodologies - which work by removing the danger from system modifications, not by avoiding modifications altogether.
The CUPID Design Properties
Section titled “The CUPID Design Properties”When evaluating infrastructure component design, the CUPID framework (Daniel Terhorst-North) provides five assessable properties that make infrastructure “a joy to work with.” They are not rigid rules - they are trade-off lenses.
| Property | What it means for IaC |
|---|---|
| Composable | Can be provisioned, tested, and delivered independently. Minimal surface area, explicit interfaces. |
| Unix philosophy | Does one thing well. Single focused purpose, consistent usage model. Maps directly to high cohesion. |
| Predictable | Deterministic and observable. An engineer can know what resources will be provisioned, what’s happening during apply, and what the final state looks like. |
| Idiomatic | Feels natural to anyone familiar with the platform and resources being used. No surprises in usage patterns. |
| Domain-based | Organized around the capability it provides, not the underlying technical implementation. |
CUPID properties are interdependent: designing for Unix philosophy naturally produces high cohesion; designing for Composability forces loose coupling and clean interfaces.
Cohesion and Coupling
Section titled “Cohesion and Coupling”Every infrastructure component design decision comes down to two questions:
- How should elements be grouped?
- How should dependencies between groups be managed?
Cohesion - Internal Relationships
Section titled “Cohesion - Internal Relationships”Cohesion measures how closely related the elements inside a single component are.
| Cohesion level | Characteristics | Risk |
|---|---|---|
| High cohesion | All elements serve one unified purpose | Low blast radius, easy to test, change-safe |
| Low cohesion | Loosely related elements bundled together | Forces full-component deploys for small changes; harder to test |
Rule of thumb: Group elements based on how frequently they change together. If two elements are rarely modified in the same commit, they probably belong in separate components. Analyzing historical git commits is a practical way to identify natural grouping boundaries.
Coupling - External Relationships
Section titled “Coupling - External Relationships”When you split a large component into smaller ones (to improve cohesion), you shift the complexity into the relationships between them. Coupling measures how tightly those relationships are.
| Coupling level | Characteristics |
|---|---|
| Tight coupling | Changing one component regularly requires changing another |
| Loose coupling | Components have a dependency, but can typically be updated independently |
The goal: High cohesion within components, loose coupling between them.
Providers, Consumers, and Interfaces
Section titled “Providers, Consumers, and Interfaces”When infrastructure is broken into components, dependencies create provider–consumer relationships:
- Provider - a component that defines and provisions shared resources (VPCs, subnets, load balancers, IAM policies).
- Consumer - a component that relies on resources created by a provider (e.g., a GKE node pool that needs to be placed inside a provider’s subnet).
Hard rule: circular dependencies must never exist. A provider must never consume resources from any of its own direct or indirect consumers.
Explicit Interface Contracts
Section titled “Explicit Interface Contracts”Dependencies must be explicitly defined - never implicit.
Implicit interfaces develop when one team quietly relies on resources owned by another without formalizing the dependency. Example: a monitoring service builds VMs into subnets managed by the container team. When the container team restructures those subnets, the monitoring service silently breaks.
Explicit interface contracts require:
- The provider declares exactly what it exports (subnet IDs, bucket names, service account emails)
- The consumer declares exactly what it requires
- Both sides agree to maintain the contract
Organizations should standardize how contracts are expressed - declared Terraform outputs written to a config registry, naming conventions, resource tagging - and treat breaking changes with the same care as a public API change.
Component-Level vs. Resource-Level Dependencies
Section titled “Component-Level vs. Resource-Level Dependencies”| Dependency type | How it works | Why it breaks |
|---|---|---|
| Resource-level (bad) | Consumer hard-codes a provider’s resource names, tags, or IDs | Provider renames or restructures → consumer breaks; requires coordinated cross-team update |
| Component-level (good) | Provider exports identifiers to a registry; consumer reads from registry | Provider can restructure internals freely as long as it keeps exporting the same identifiers |
The Principle of Least Knowledge
Section titled “The Principle of Least Knowledge”The formal name for this pattern is the Law of Demeter (Principle of Least Knowledge): a consumer component should never depend on the internal implementation details of its providers. It should only know what it needs to connect - not how that thing was built.
Design-Driven Testing
Section titled “Design-Driven Testing”In IaC, testability is not a quality concern bolted on after design - it is a design concern.
Testing an infrastructure component in isolation requires that the component can be provisioned without pulling in a large chain of dependencies. If it cannot, the component is over-coupled and will resist automated delivery.
This creates a forcing function: rigorous isolated testing drives good design. Components that are hard to test in isolation are components with weak cohesion or tight coupling. Fixing the test problem means fixing the design problem.
The Agile concept of Test-Driven Development (TDD) applies here not just as a mechanical practice, but as an architectural discipline - writing tests first forces engineers to confront coupling and cohesion problems before they become expensive to fix.
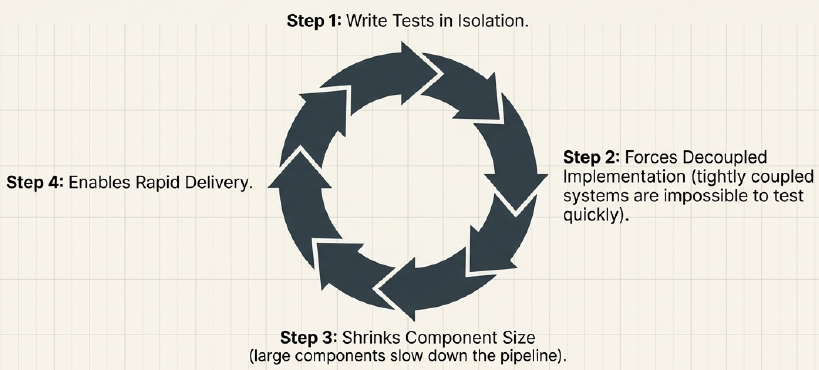
Design Forces
Section titled “Design Forces”Design forces are the requirements and constraints that shape where component boundaries are drawn. They operate across four lifecycle stages:
Source Code Forces
Section titled “Source Code Forces”| Force | Influence |
|---|---|
| Code ownership | Repository permissions naturally push code to follow team ownership boundaries |
| Working sets | Group code that engineers change together as part of a single task |
| Delivery scope | Keep a component’s code together so it can be built and tested as one unit |
Packaging and Deployment Forces
Section titled “Packaging and Deployment Forces”| Force | Influence |
|---|---|
| Downtime management | Smaller, independently deliverable components reduce the scope of workloads affected by any single change |
| Workload alignment | Shared runtime resources (e.g., one database for multiple apps) create deployment coupling - a database can’t be upgraded until all its apps are ready |
| Compliance | Isolate regulated infrastructure into dedicated components so lightweight delivery processes can apply to the rest |
Runtime Forces
Section titled “Runtime Forces”| Force | Influence |
|---|---|
| Scaling | Isolate bottleneck resources so they can scale independently |
| Geographic distribution | Separate centralized shared resources from regional replicas |
| Resilience | Storage and compute have different recovery requirements - separate them so disaster recovery is simpler |
| Data regulation | Credit card data, tenant-isolated data - each needs distinct infrastructure instances with enforced security boundaries |
| Component lifecycles | Slow-to-provision resources (load balancer rules) and fast-cycling resources (test compute) should live in separate components to avoid blocking test pipelines |
| Hosting costs | Avoid unnecessary replication; optimize placement for both cost and carbon footprint |
Cross-Lifecycle Forces
Section titled “Cross-Lifecycle Forces”| Force | Influence |
|---|---|
| Cognitive size | Large components are harder to understand, slower to test, and have a wider blast radius. Keep them small - but manage the integration complexity that follows. |
| Change scope | Minimize the number of components that must change to deliver a single routine modification. Use commit history to identify natural cohesion clusters. |
| Conway’s Law | Systems reflect the communication structures of the organizations that build them. Align component boundaries with team ownership to avoid cross-team modification friction. |
| Cost of ownership | Standardized, reusable components reduce the total amount of custom code and make routine patching easier across the organization. |
| Security | See section below. |
| Lightweight governance | Centralized control must be balanced with team autonomy. Over-governance creates bottlenecks; under-governance creates sprawl. |
Infrastructure Security as a Design Concern
Section titled “Infrastructure Security as a Design Concern”Cloud infrastructure introduces a security attack vector that does not exist in traditional data centers: the IaaS API itself.
Traditional network segmentation (public segments, DMZs, internal storage networks) defends against network-based attacks. In a cloud environment, an attacker who gains IaaS API credentials can bypass all network layers entirely - directly creating, modifying, or destroying infrastructure through the API.
This fundamentally changes how component boundaries must be designed:
| Strategy | What it achieves |
|---|---|
| Separate IaaS accounts per security domain | API credentials for one account cannot affect resources in another |
| Risk-based grouping | Evaluate the specific blast radius if each account’s API credentials are compromised |
| Monitoring isolation | Host alerting and monitoring in a separate account - a compromised workload account cannot silence its own alerts |
Lifecycle Stages of Infrastructure Code
Section titled “Lifecycle Stages of Infrastructure Code”The structure of infrastructure code looks different depending on which lifecycle stage you’re examining. Design decisions at one stage ripple into others.
| Stage | What engineers do | Design concerns | How it manifests |
|---|---|---|---|
| Source code | Edit and test | Optimize for understanding, sharing, collaborating, changing | Repository structure, folder layout, file organization |
| Package | Prepare for deployment | Fast and reliable feedback on production-readiness | Packages, branches, tags, deployment artifacts |
| Deployment | Execute to provision | Speed and reliability of provisioning | Desired state model in memory; determines deployment duration |
| Live resources | Run workloads | Operability and troubleshooting | Actual cloud resources on the IaaS platform |
Runtime requirements (scaling, resilience, data isolation) sometimes require only parameterization - the same code deployed multiple times with different config. Other times they require entirely separate source code components.
Lightweight Governance
Section titled “Lightweight Governance”Modern platform engineering must balance centralized control with team autonomy. Heavy-handed governance creates approval bottlenecks; no governance creates fragmentation and sprawl.
Lightweight governance establishes standard patterns, shared modules, and policy guardrails while allowing teams to operate independently within those boundaries. It is a key element of the EDGE model used by Agile organizations for digital transformation.
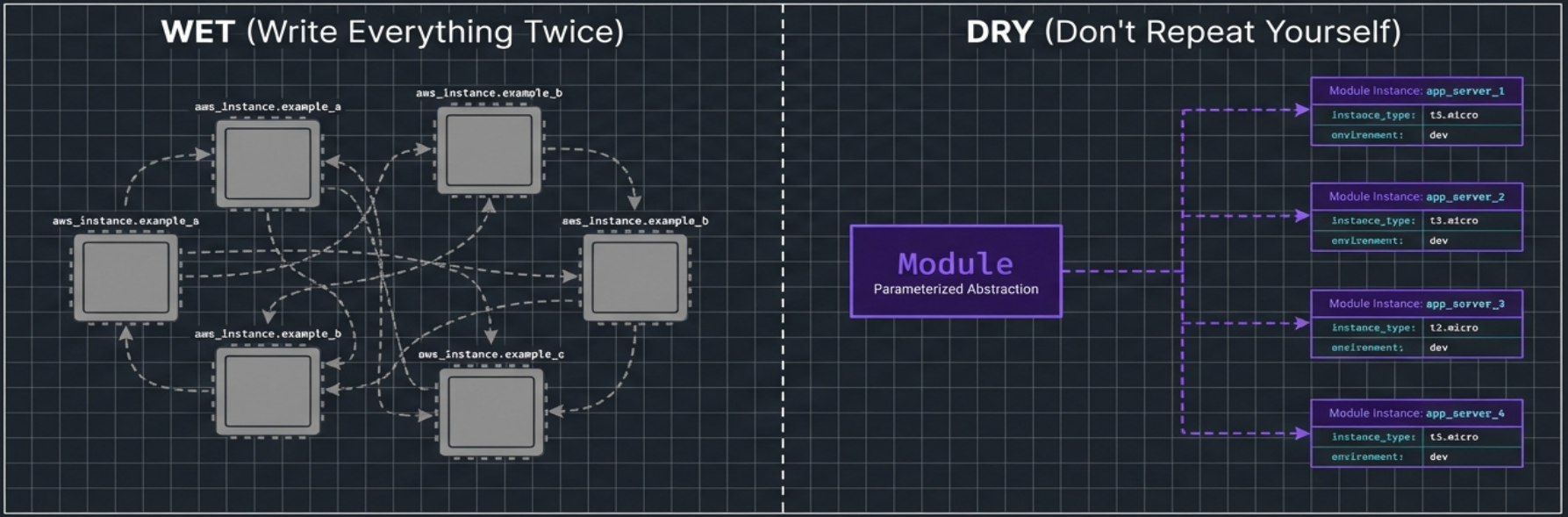
Terraform Modules in Practice
Section titled “Terraform Modules in Practice”The design patterns above are tool-agnostic. In Terraform and OpenTofu, the primary mechanism for implementing them is the module - a reusable package of pure HCL that takes input parameters, executes internal logic, and returns outputs.
Module Types
Section titled “Module Types”| Type | Role | Where providers are configured |
|---|---|---|
| Root module | Entry point for a Terraform project - running terraform init here creates a workspace | Yes - the provider block lives here |
| Shared module | Reusable module pulled from a registry or Git repository | No - inherits providers from the calling root |
| Submodule | A child module nested inside a parent module’s modules/ directory, used to decompose complexity | No - inherits providers from the parent |
Module Block and Meta-Arguments
Section titled “Module Block and Meta-Arguments”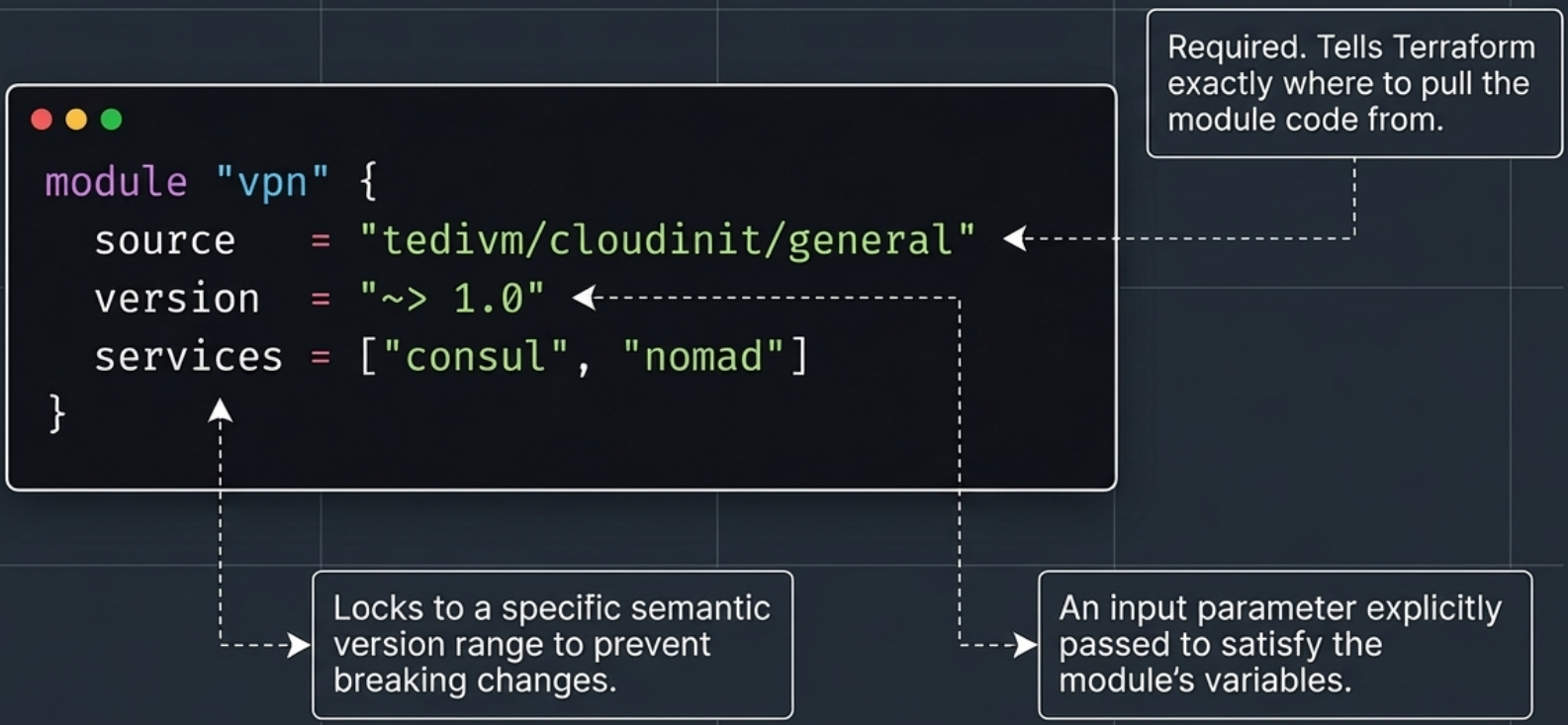
Modules are called using the module block, which supports three meta-arguments not found on standard resources:
| Meta-argument | Required | Purpose |
|---|---|---|
source | Yes | Where to download the module - local path, Git URL, or registry address |
version | Recommended | Locks the module to a specific version range when pulling from a registry |
providers | Optional | Passes specific provider aliases from the caller into the nested module |
Standard File Structure
Section titled “Standard File Structure”The Terraform community follows a conventional layout for modules:
| File / Directory | Purpose |
|---|---|
main.tf | Primary resource definitions |
variables.tf | Input variable declarations |
output.tf | Output attribute definitions |
README.md | Documentation - automatically parsed by module registries |
modules/ | Submodules for internal decomposition |
templates/ | Template files referenced by resources |
examples/ | Usage examples for consumers |
Module Registries
Section titled “Module Registries”| Registry type | Examples | Authentication |
|---|---|---|
| Public | Terraform Registry (~12,000 modules) | None - open access |
| Private | Terraform Cloud, Spacelift, self-hosted | Tokens via terraform login |
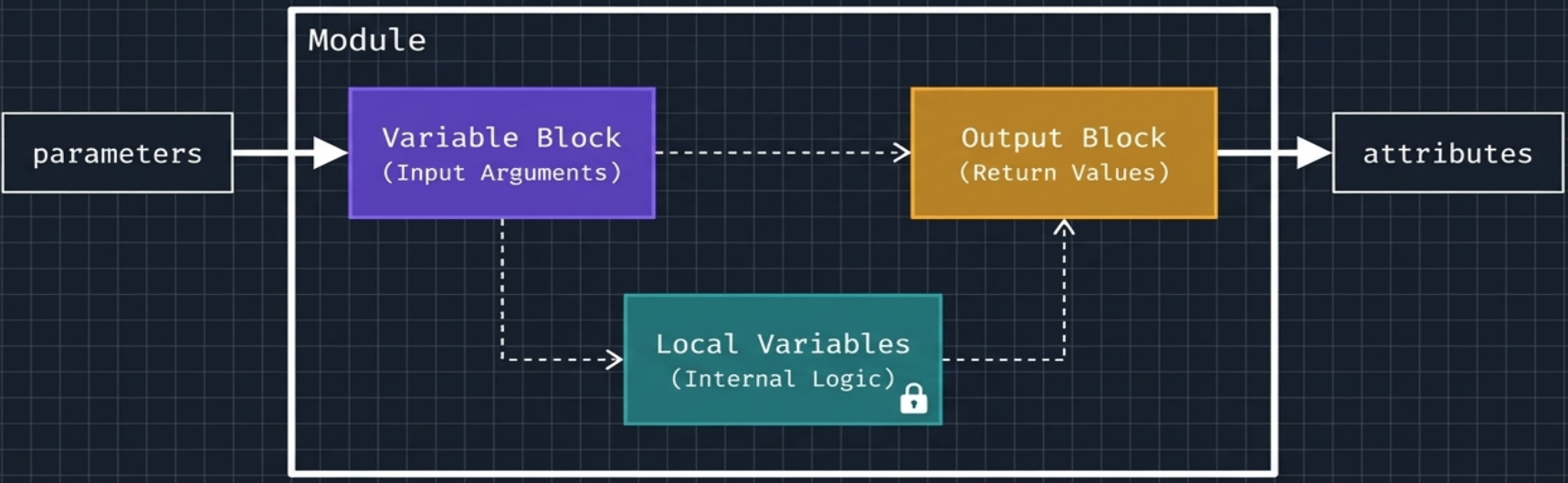
Variable Scoping Inside Modules
Section titled “Variable Scoping Inside Modules”All Terraform variables are constants - their values cannot change during a run. A module’s data flow uses three scopes:
| Scope | Block | Direction | Visibility |
|---|---|---|---|
| Input | variable | Inward (caller → module) | Configurable by the caller |
| Local | locals | Internal only | Private to the module |
| Output | output | Outward (module → caller) | Exposed to the caller and downstream resources |

- Inputs accept a
description,type,default, and optionalsensitiveflag (suppresses log output but does not encrypt state) - Outputs can also be
sensitiveand can declare explicitdepends_onfor ordering - Locals are used for internal processing, avoiding circular references, and caching computed values
Type System
Section titled “Type System”Terraform enforces variable types to catch misconfigurations early:
| Category | Types |
|---|---|
| Primitive | string (supports interpolation), number (int, float, negative), bool |
| Collection | list (ordered, same type), set (unordered, no duplicates) |
| Structural | tuple (fixed length, mixed types), object (keyed, typed fields, optional keys), map (keyed, same-type values) |
| Special | null (value not set), any (accepts any type) |
Input Validation
Section titled “Input Validation”The validation subblock inside a variable block enforces constraints before Terraform reaches the plan stage:
variable "environment" { type = string description = "Deployment environment"
validation { condition = contains(["dev", "staging", "prod"], var.environment) error_message = "Environment must be dev, staging, or prod." }}Conditions can check string length, integer ranges, regex patterns, or set membership. Failed validations produce the custom error_message immediately - no resources are evaluated.
Refactoring to a Reusable Module
Section titled “Refactoring to a Reusable Module”
The typical workflow for converting a hard-coded root module into a reusable, publishable module:
- Extract variables - replace every hard-coded value with an input variable
- Add outputs - expose the attributes that consumers will need (IDs, endpoints, ARNs)
- Test in a separate workspace - instantiate the refactored module from a clean root to verify it works in isolation
- Publish - push to a Git host (GitHub, GitLab) or a module registry for team-wide consumption
- Version - tag releases with semantic versioning so consumers can pin to stable versions
When to Create a Module
Section titled “When to Create a Module”Modules introduce real overhead - versioning, dependency management, a separate build step, and an abstraction layer that every teammate must understand. That overhead is worth paying only when the benefit is clear.
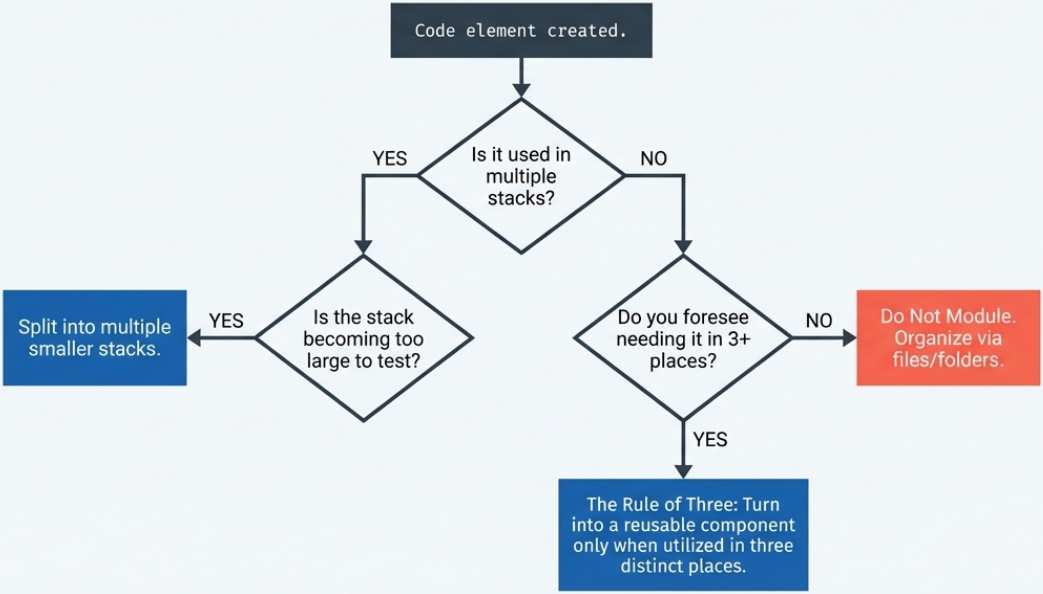
The Three Questions
Section titled “The Three Questions”Before extracting code into a module, ask:
| Question | If yes → | If no → |
|---|---|---|
| Will this code be used in 3+ distinct places? | Module is likely justified | Favour duplication or file/folder organisation |
| Does wrapping it genuinely simplify the interface? | Good candidate for a Facade or Bundle | Risk of creating an Obfuscation Module |
| Do the resources inside always provision together? | Bundle Module makes sense | Split into separate, focused modules |
Create a Module When…
Section titled “Create a Module When…”- The same group of resources is provisioned across three or more stacks with only configuration differences
- The underlying resource API is genuinely complex and a simplified interface would save consumers from needing to understand it
- You want to enforce a secure or approved configuration as the only option available to consumers
- A platform team needs to offer self-service infrastructure components to stream-aligned teams
- You need to version and distribute the code independently of the stacks that consume it
Don’t Create a Module When…
Section titled “Don’t Create a Module When…”- The code exists in only one place - use files and folders to organise; reach for a module only when a second or third consumer appears
- The wrapper would pass all parameters straight through without hiding complexity (that’s an Obfuscation Module)
- The module would need heavy conditionals to handle divergent use cases - split it into separate focused modules instead
- You’re only trying to break up a large stack - splitting into separately deployable stacks solves the deployment problem; modules alone do not
- You’d be creating a module to satisfy a premature DRY instinct - YAGNI applies here
Infrastructure Code Library Patterns
Section titled “Infrastructure Code Library Patterns”Code libraries (Terraform modules) are the primary mechanism for packaging and reusing infrastructure logic. How they are designed determines whether they simplify your codebase or silently complicate it. The patterns below describe the design spectrum from well-focused modules to antipatterns that create more problems than they solve.
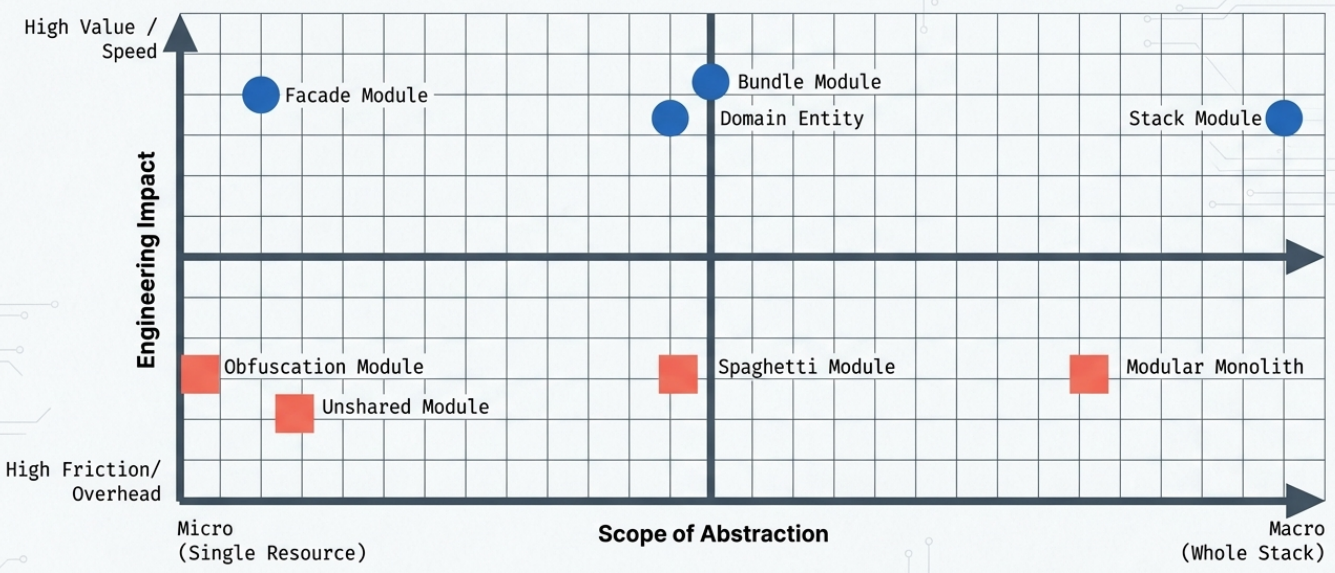
Pattern Overview
Section titled “Pattern Overview”| Pattern | Type | What it does | Language |
|---|---|---|---|
| Facade Module | Pattern | Wraps a single resource with a simplified interface | Declarative |
| Bundle Module | Pattern | Groups multiple related resources under one interface | Declarative |
| Infrastructure Domain Entity | Pattern | Dynamically provisions resources based on high-level business inputs | Imperative |
| Stack Module | Pattern | Implements an entire deployable stack as a library | Either |
| Obfuscation Module | Antipattern | Wraps a resource without simplifying it | - |
| Unshared Module | Antipattern | A module used in exactly one place | - |
| Spaghetti Module | Antipattern | An over-configured module that generates wildly different results | - |
| Modular Monolith | Antipattern | A monolith split into modules but still deployed as one unit | - |
Facade Module
Section titled “Facade Module”A facade module (also called a wrapper module) wraps a single infrastructure resource and exposes only a few essential parameters while hardcoding the rest internally.
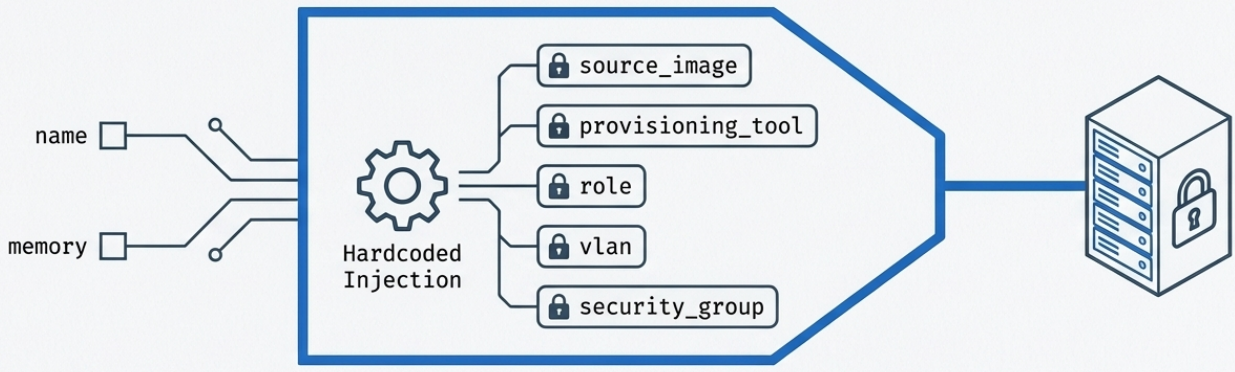
Example: a facade for a virtual server might expose only name and memory, while internally hardcoding the source image, provisioning tool, server role, and network configuration.
| Benefit | Trade-off |
|---|---|
| Simpler, more readable stack code | Limits flexibility - not suitable for every use case |
| Standardizes secure, approved configurations | Adds an abstraction layer that obscures what’s actually provisioned |
| Centralized updates propagate to all consumers | Maintenance and debugging overhead from the extra layer |
Best for: simple, repetitive use cases where the underlying resource API is overly complex and most options are irrelevant to the consumer.
Bundle Module
Section titled “Bundle Module”A bundle module groups a cohesive collection of related resources under a single interface - essentially a facade applied to multiple resources instead of one.
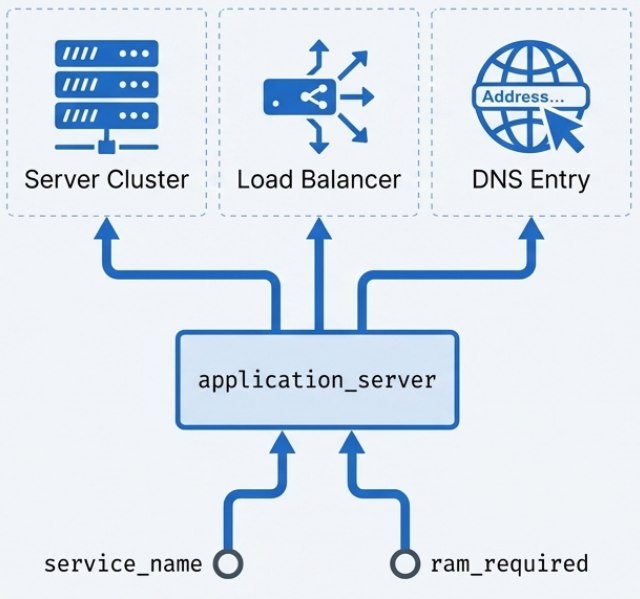
Example: an application_server bundle might accept app_name, cluster_size, and ram. Internally it provisions the server cluster, configures a load balancer, and sets up DNS - wiring everything together.
| Benefit | Trade-off |
|---|---|
| Eliminates boilerplate across stacks | May provision more resources than needed in some cases |
| Captures institutional knowledge about how resources connect | Users must understand everything it provisions to avoid over-provisioning |
Best for: declarative languages where the resources involved do not vary across use cases. If resources change based on the situation, create separate modules or use an Infrastructure Domain Entity instead.
Infrastructure Domain Entity
Section titled “Infrastructure Domain Entity”A domain entity implements a high-level stack component by dynamically provisioning resources based on business-level input parameters - not technical ones.
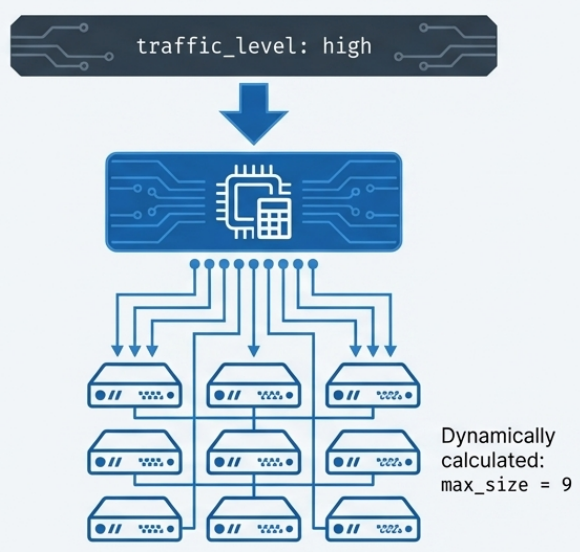
Example: a Java application infrastructure entity accepts traffic_level (high, medium, low) and dynamically adjusts cluster sizing, auto-scaling thresholds, and resource allocation.
| Aspect | Detail |
|---|---|
| Approach | Top-down - starts from what the use case requires, not from the resources to create |
| Language | Must be imperative (CDK, Pulumi, CDKTF) - declarative languages lack the dynamic logic required |
| Design method | Derived from Domain-Driven Design (DDD) - treat infrastructure delivery as a domain in its own right |
| Best for | Platform teams building robust, configurable components for other teams to consume |
Key insight: the bundle module and the domain entity both group resources, but from opposite directions. Bundles are bottom-up (starting with resources); domain entities are top-down (starting with requirements).
Stack Module
Section titled “Stack Module”The stack module pattern (also called a no-code module) uses a code library to implement an entire deployable stack. A separate wrapper stack project imports the module and provides instance-specific configuration.
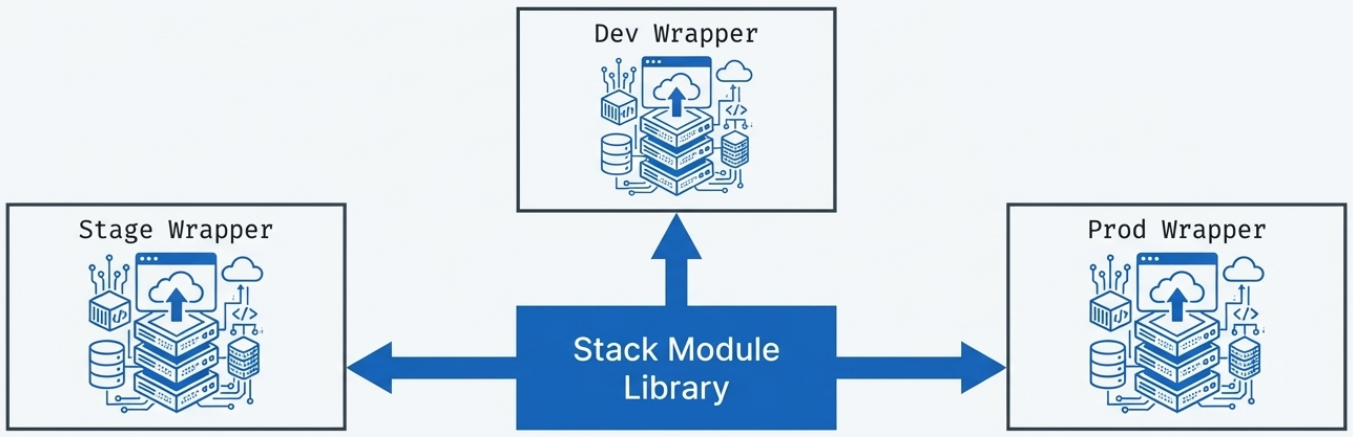
This pattern is already covered in detail in Stacks & Components - The Stack Module Pattern. Its inclusion here is for completeness in the library patterns taxonomy.
Why it exists: Terraform and OpenTofu have strong built-in support for distributing, versioning, and sharing modules - but lack equivalent support for stacks. The stack module pattern is a practical workaround for this tool limitation. Some platforms (e.g., HCP Terraform’s no-code provisioning) automate wrapper generation entirely.
Obfuscation Module (Antipattern)
Section titled “Obfuscation Module (Antipattern)”An obfuscation module wraps infrastructure code without simplifying it or adding value - it just passes parameters through to the underlying resource.

How it happens:
- Misguided DRY - a developer wraps a commonly used resource (security group, load balancer) in a module just because it appears in multiple places, without actually simplifying the interface
- Custom language syndrome - attempting to build a proprietary language on top of the stack tool’s native constructs
The result: more code to maintain, cognitive overhead for teammates who must learn the custom module, and extra moving parts in the build pipeline - all without any reduction in complexity.
Resolution: if a module doesn’t add enough value to justify its overhead, refactor by replacing module usages with direct stack language code. If the goal is simplifying infrastructure for non-specialists, use higher-level abstractions (compositions, stacks) instead of wrapping low-level resources.
Unshared Module (Antipattern)
Section titled “Unshared Module (Antipattern)”A module that is used in exactly one place - created to organize a growing stack project rather than to enable reuse.
Why it’s a problem: modules introduce versioning, dependency management, and build overhead. Creating a reusable component when you don’t need to reuse it is a textbook case of YAGNI (You Aren’t Gonna Need It).
Better alternatives:
- Split the stack into multiple smaller, independently deployable stacks
- Organize with files and folders - structure the code for readability without the overhead of module management
Spaghetti Module (Antipattern)
Section titled “Spaghetti Module (Antipattern)”A module so configurable that it generates wildly different infrastructure depending on the parameters it receives - filled with complex conditionals and excessive moving parts.
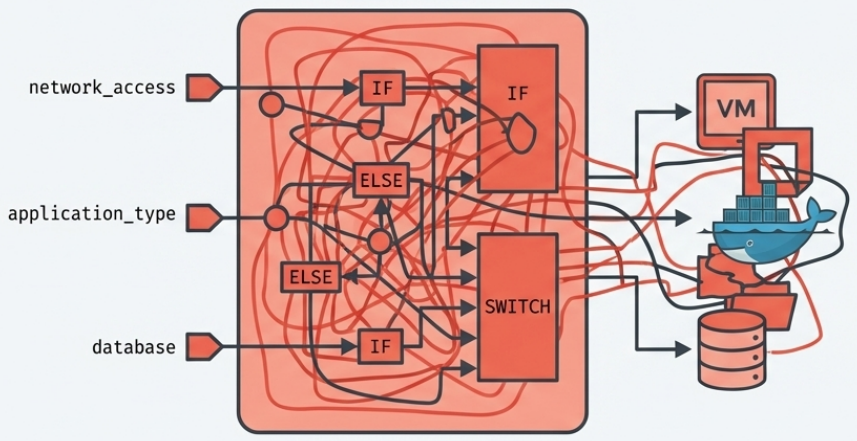
Example: a single module that conditionally assigns servers to different network segments, optionally creates a database cluster, and dynamically switches between VMs and container instances based on an app_type parameter.
How it happens:
- A facade or bundle module slowly accumulates edge-case conditionals
- A developer attempts to build a domain entity using a declarative language (which lacks the required dynamic logic)
Symptoms:
- Struggling to build pipelines and write automated tests for the module in isolation
- Changes frequently break unrelated functionality
- The module is harder to understand than the raw resources it wraps
Resolution: split into multiple focused modules, each with a tight remit. One module for Java application servers, another for MySQL clusters - not one module that tries to handle both.
Modular Monolith (Antipattern)
Section titled “Modular Monolith (Antipattern)”A monolithic stack that has been split into modules but still deployed as a single unit. The code is more organized, but the operational problems remain:
- Deployments are still slow
- A change to one module still risks impacting everything in the stack
- Feedback loops for testing and delivery are unchanged
Why it fails: the root problem with a monolith is not code organization - it is deployment scope. Splitting code into modules addresses the code problem but leaves the deployment problem untouched.
Resolution: don’t just modularize the code - split the monolith into smaller, separately deployable stacks. See Stack Sizing Patterns for guidance on how to size them.